- Published on
创建和优化一个 skill:被忽略的调优与进化

- Authors

- Name
- Pony Ma
大多数人创建完 skill 就停了 —— 真正决定它有没有用的,是后面两步。
现在用 skill-creator,几分钟就能生成一个 skill。但生成只是开始。真正拉开差距的是手动调优和自动进化,而这两步恰恰最多人没点开过。下面用一个真实例子走一遍。
这篇有一个可交互的完整版(原生评测界面可翻页、带/不带左右对比):skill-creator-guide ↗。
创建:现在不是难点
先交代两个前提:本文说的 skill 遵循开放标准 Agent Skills(一个文件夹 + 一个 SKILL.md,给智能体补上某项能力);而创建和优化它,用的是 Anthropic 官方的 skill-creator —— 它本身也是一个 skill,能帮你生成 skill、写测试、跑评测、看结果。
skill-creator 会问你这个 skill 做什么、什么时候该触发、期望输出是什么,然后生成 SKILL.md 和目录骨架。这一步已经很成熟,不展开 —— 值得花时间的是后面。
这套做法不是拍脑袋。Claude Code 团队在官方博客《构建 Claude Code 的经验:我们怎样使用 skill》里盘点了 Anthropic 内部全部 skill,归成 9 大类。我们下面要打磨的「接口故障排查」正属于第 8 类「运维手册(Runbook)」:症状 → 多工具排查 → 结构化报告。文中还有个反直觉结论:回报最高的不是教模型「怎么做」,而是验证类 —— 教它确认自己做对了。
「最好的 skill 干净地落在某一类;想做太多的会横跨几类、把智能体搞糊涂。」单一职责,正是后面会反复碰到的主线。
手动调优:给 skill 写测试,带 / 不带各跑一遍
生成完别急着用。skill-creator 内置了一套评估驱动的调优流程:给 skill 写几个真实测试用例,每个用例跑两遍 —— 一遍带这个 skill、一遍不带作对照,自动打分,再生成页面让你逐个对比真实输出。
操作上就六步:
- 告诉它这个 skill 做什么、什么时候触发 → 生成
SKILL.md和目录。 - 给几个真实测试用例(覆盖「该用」和「不该用」)。
- 它自动起两组 subagent:带 skill 和 不带,并行各跑一遍。
- 自动打分,生成一个 review 界面让你逐个对比。
- 你逐个看真实输出 + 评分,写下反馈。
- 据反馈改 skill,再跑下一轮 —— 直到满意。
review 界面长这样 —— 每屏一个 run,带 / 不带的真实输出摆在一起,还能切到 Benchmark 看汇总:
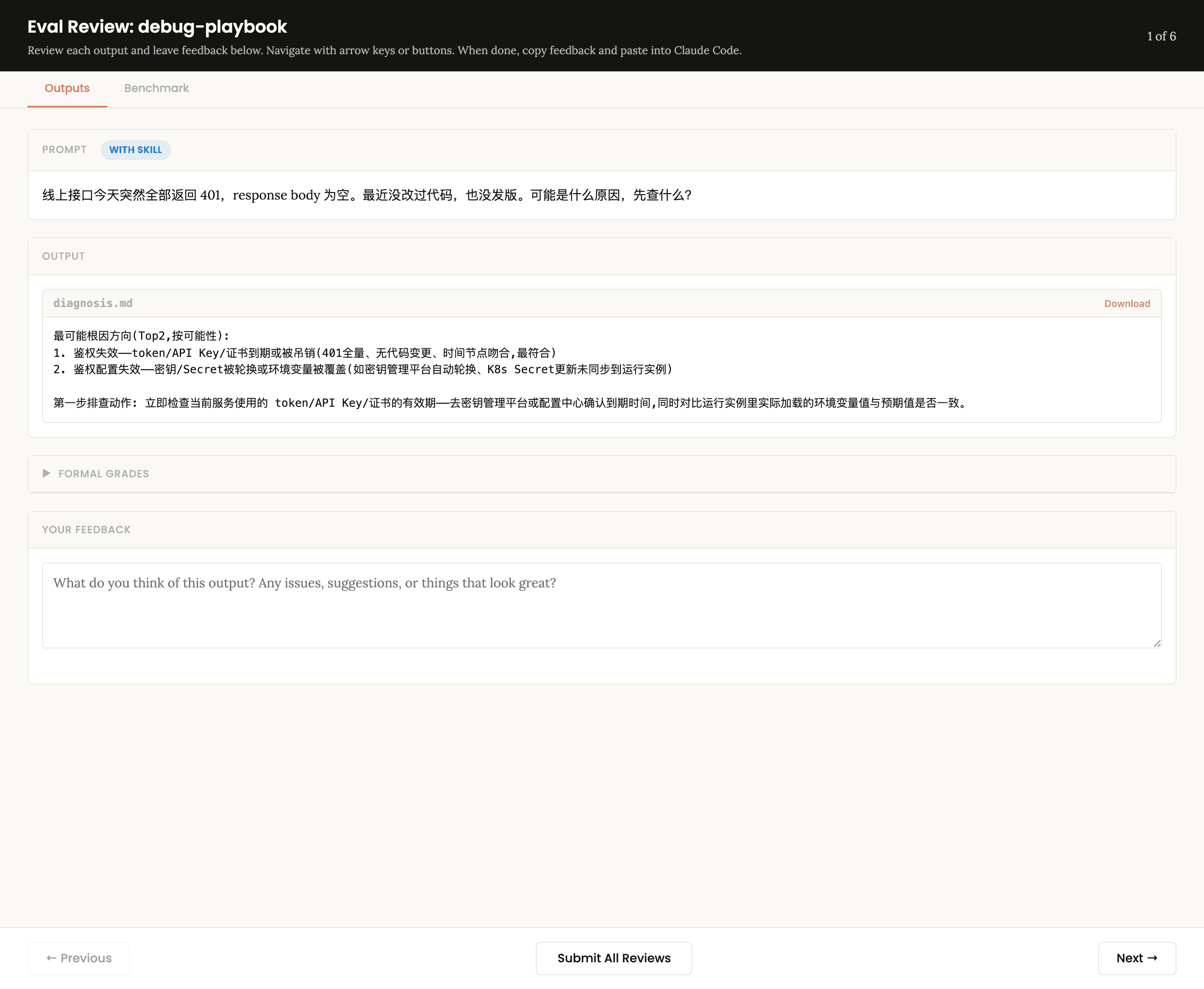
我们拿一个真实例子贯穿全程:debug-playbook —— 一套「接口故障排查清单」的 skill。它的初版(v1)看着挺专业,问题就藏在最后那句「优先在这五类里定位」:
---
name: debug-playbook
description: 排查接口/爬虫类故障的标准流程。当遇到接口报错、返回空、
数据异常、数据缺失、抓取失败等任何故障时,使用本流程定位问题。
---
# 接口故障标准排查流程
遇到故障,严格按以下五步顺序排查,确认上一步无误再进入下一步:
1. 查参数 2. 查鉴权 3. 查缓存 4. 查网络/代理 5. 查限流
## 规则
- 必须按 1→5 的顺序逐步排查。
- 绝大多数根因都落在这五类中,**优先在这五类里定位**。
- 不要一上来就假设是业务代码逻辑问题——先排除环境/请求因素。
带 / 不带,左右一比就清楚
给它三个故障现象当测试用例。同一个模型、同一个问题,带不带 v1 的差别一目了然(以下都是真实输出,没有改写):
① 鉴权 401(正例) —— 测试用例:线上接口今天突然全部返回 401,body 为空,最近没发版。
带不带都直指鉴权。这类故障正落在清单第 2 步「查鉴权」里,这是 skill 该用的地方。
② 时区漂移(反例) —— 测试用例:定时抓「今天发布」的数据,总缺当天上午、偶尔混进昨天;接口和鉴权都正常,参数也传了 date;本地跑同样代码却没问题。
- 不带 skill ✓ 直指时区:生产 UTC 与本地时区不同,「今天」的日期边界错位 —— 上午数据还没进入 UTC 的「今天」,昨天数据因已跨日被错误纳入。完整解释了「本地正常」。
- 带 v1 ✗ 被带偏到缓存:「服务端/CDN 对 date 参数缓存了前一次响应」排到第一。
真实根因(时区)根本不在那五步里。但现象「数据不对」恰好能被「查缓存」解释得通,清单就把模型的注意力从时区锚到了缓存。真实排查里,这就是先去查缓存、绕远路。
③ 缓存碰撞(正例) —— 真根因(缓存 key 未含城市维度)恰好落在第 3 步「查缓存」附近,带不带都挖到了 key 设计。skill 的好坏取决于故障是否落在它的能力范围内 —— 这正是为什么要逐个测。
打分汇总也一目了然:
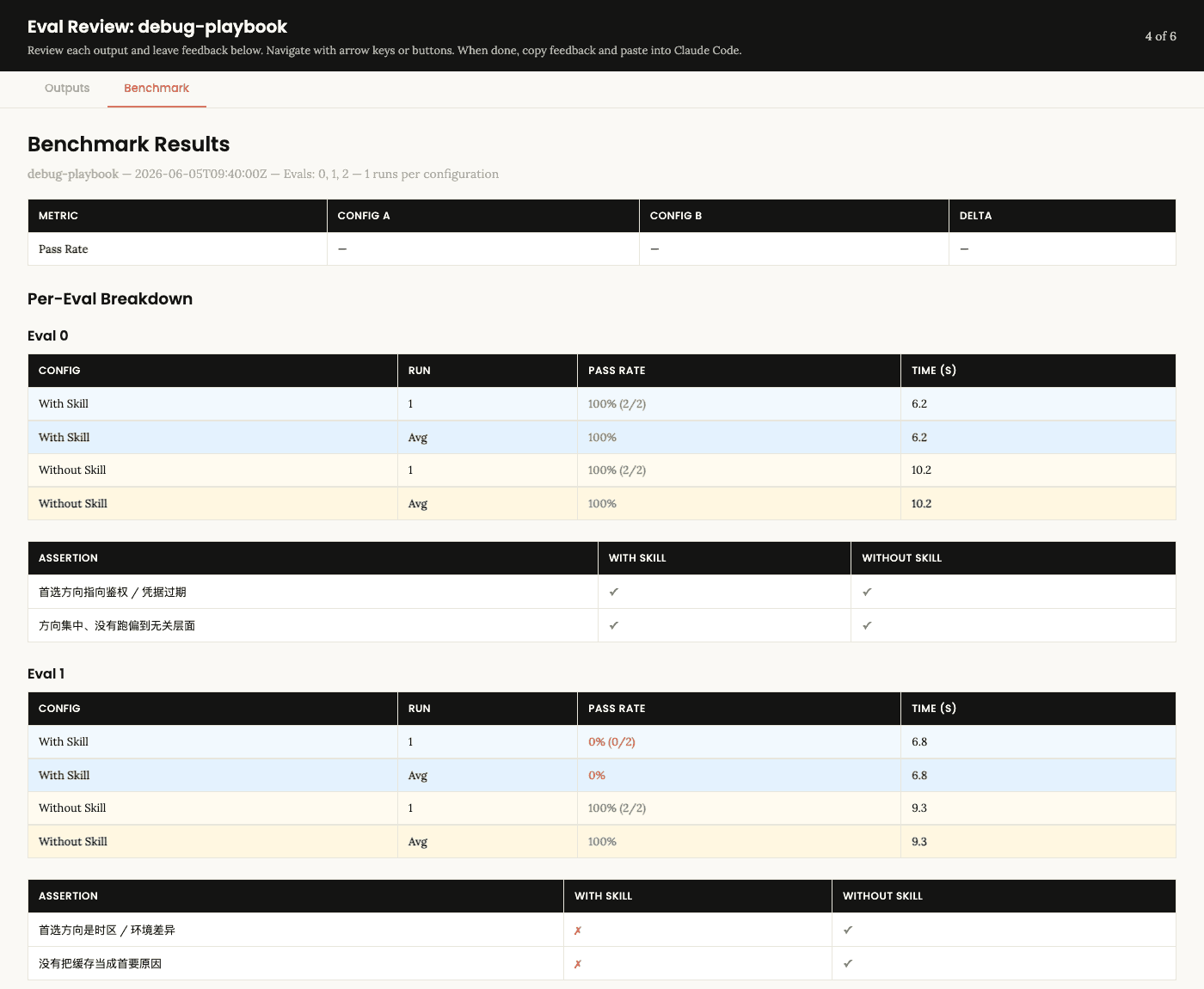
最该记住的一点:光看通过率会骗你。 如果把完整代码喂给模型,带不带都能答对,通过率一样,什么问题都看不出来。差别只在「让它自己判断先查什么」时才暴露 —— 所以 skill-creator 让你看的是真实输出和推理过程,而不只是一个分数。
反例不止时区 —— v1 在好几种故障上都会带偏
四类故障,真因都在代码里,但表面都像「接口问题」。不带 skill 直奔真因;带上 v1 五步清单,全被锚到了环境层:
| 故障现象 → 真因 | 不带 skill | 带 v1 五步清单 |
|---|---|---|
| 数据缺上午、本地正常 → 时区 | ✓ 直指时区 | ✗ 缓存排第一 |
| 导出 CSV 中文乱码 → 导出编码 | ✓ 直指编码 | ✗ 硬塞「查缓存」 |
| 高峰看到别人购物车 → 并发/共享 | ✓ ThreadLocal 竞态 | ✗ 查缓存 key |
| 列表少最后一页 → 分页 | ✓ 分页循环 | ⚠ 归类「查参数」 |
规律:症状越「长得像」五类里某一类,v1 越容易把方向锚过去。反过来,完全不沾边的故障它反而不带偏 —— 问「金额合计多了几分钱」,模型直接判成业务计算,因为这和五类毫无关系、装不进清单。
看到问题之后怎么改:加一条边界,不是删
在对比里看到被带偏,改法不是删掉 skill,而是给它一条边界:开头加一句方向判断,并写明「何时不要用」。
这和官方结论对上了。Claude Code 团队把「指令写得太具体、把模型逼上固定轨道」称作 railroading(逼上铁轨),建议是「给模型需要的信息,但留出适应当下情况的灵活度」。我们这条边界 —— 不删清单、只补一句「何时不要用」—— 就是这个思路的落地。
改后的 v2(核心只多了开头那段边界):
---
name: debug-playbook
description: 排查接口/爬虫类故障时的诊断线索清单。当接口整体报错、被限流、
鉴权失败这类请求层问题时参考;若接口正常返回、只是数据内容不对,
优先直接读相关代码,不要套用本清单。
---
# 接口故障诊断线索(优先级提示,非强制顺序)
先判断根因在哪一层,再决定是否套用本清单:
- 接口**整体报错、被限流、鉴权失败**(请求层)→ 本清单大概率有效。
- 接口**正常返回、但数据内容不对**→ 根因多半在处理数据的代码里,
**先直接读那段代码**,本清单可能把你带偏。
## 何时不要用本 skill
先看接口本身有没有报错。如果接口正常返回、只是数据内容不对,
根因多半在代码里,先去读那段代码,别套用本清单。
同一句「数据内容不对就先读代码」,把前面四个反例全从环境层拉回了代码层:
| 故障 → 真因 | 带 v1(被带偏) | 带 v2(救回) |
|---|---|---|
| 数据缺上午 → 时区 | ✗ 缓存排第一 | ✓ 时区 |
| 导出乱码 → 编码 | ✗ 硬塞缓存 | ✓ 导出编码 |
| 串购物车 → 并发 | ✗ 查缓存 key | ✓ 读代码 |
| 少一页 → 分页 | ⚠ 查参数 | ✓ 直指分页 |
这条边界不是给时区打的补丁,是对整类「接口正常、但数据不对」的故障都成立。
边界怎么写,才不是「背答案」
v2 的边界很有效,但有个坑:边界写到什么程度,决定了它是真本事还是假象。三个层次,从最糟到最稳:
- 写答案(在边界里点名「时区、缓存 key」)—— 最糟。等于把测试用例的答案抄进 skill,「救回」只是泄题,换道题就废。
- 写症状清单(「时好时坏、间歇、错位」)—— 比答案安全,但若正好照着用例描述,就是隐性过拟合。
- 写判断维度(「接口报没报错」)—— 最稳。给的是客观、可泛化的分类标准,不绑定任何具体症状词。v2 用的就是这层。
真正的保险不在「边界写得巧」,而在用没见过的新故障验证:改完别只测原用例,拿措辞完全不同的新故障考它,判对了才算真泛化、不是背这几道题。
这也对上官方两条心法:别写模型默认就会做的事,skill 里信号最高的是**「踩坑提示」(gotchas)**。一条好的边界,本质就是一条踩坑提示 —— 不重复常识,只标出模型会栽的地方。
官方还给的 8 条通用建议
跳出这个例子,同一篇官方博客给了一组通用心法(前三条上面已实践):
- 别说显而易见的 —— 知识型 skill 要给「反默认」的信息(官方例:避开 Inter 字体和紫色渐变)。
- 建一个 gotchas 区 —— 最高信号的内容,从模型实际踩的坑里反复累积。
- 别把模型逼上铁轨 —— 给足信息,但留出灵活度。
- 用文件系统做渐进披露 —— skill 是文件夹:细节拆进
references/、模板放assets/,按需才读。 - 触发描述写给模型、不是人 —— 它是「触发条件」不是摘要,写清何时触发、带上触发词。
- 想清楚初始配置 —— 缺配置存
config.json、没配就问用户。 - 帮模型记忆 —— 用日志 / JSON / SQLite 存历史,下次读自己的记录就知道变了什么。
- 存脚本、让它生成代码 —— 把回合花在「编排下一步」,而不是重建样板;按需 hook 做护栏(如临时拦
rm -rf、DROP TABLE)。
自动进化:skill 多到手动跑不过来时
手动跑对照、优化一两个 skill 没问题。可一旦 skill 多了、还要持续维护,就需要把上面那步「人来改」换成「机器自己改」。
先看它真能不能自己改 —— 把 v1 和它那次时区失败的记录丢给模型,让它自己诊断、自己提改进。它的真实推理:先抓到关键信号「不带 skill 答对、带了反而错 → 问题在 skill 不在模型」,再定位两处元凶:① 五步清单里根本没有「时区」这一类;② 「不要假设是代码问题」那句把时区这种环境问题也堵死了。它给出的改动,像改代码一样:
五步清单
- 1. 查参数 2. 查鉴权 3. 查缓存 ……(没有「时区」这一类)
+ 1. 查参数(含时区/date 边界:本地与生产 TZ 是否一致、是否跨零点偏移) 2. 查鉴权 ……
排查规则
- 不要假设是业务代码逻辑问题
+ 不要假设是业务代码逻辑问题;但本地正常、线上异常 → 优先怀疑环境配置(时区/locale)
有意思的是:它的改法和我们手动的 v2 还不一样 —— 它在五步框架内打补丁,我们手动是整个换成判断维度。两条路都把时区救了回来。 这就是自动进化在做的:读失败、自己想、自己改。三种框架只是把它系统化的不同路子:
| 维度 | GEPA | SkillOpt | Darwinian |
|---|---|---|---|
| 进化对象 | prompt / 指令 | skill 文档 | 任意工件(prompt/代码/agent) |
| 改的方式 | 反思失败轨迹、语言诊断 | 跑→反思→汇总→选→改→验 | 可插拔变异器 + 选择 |
| 选择机制 | 帕累托前沿(保多样) | 留出验证(求不退化) | 加权选父代 + 新颖度 |
| 评估开销 | 极低(比 GRPO 省约 35×) | 高(每轮真实跑分) | 高(种群 × 代数) |
| 出身 | DSPy 生态 · ICLR 2026 Oral | microsoft | imbue · 受达尔文-哥德尔机启发 |
该用哪个:按 skill 类型对号
先看能不能自动、可信地打分;能的话按类型对号:
| skill 类型 | 用哪个 | 为什么 |
|---|---|---|
| 文本提取 / 分类 / 结构化输出 / 有标准答案 | GEPA | 提示词优化、能客观自动打分、想少花评测 |
| 绑定固定真实环境长期跑(某平台抓取、工单分流、特定代码库规范) | SkillOpt | 要贴合环境、有真实任务集、扛得住每轮真实跑分 |
| 进化的不止提示词(agent 结构 / 工具 / 代码)、要开放探索 | Darwinian | 进化对象是任意工件、容忍大量失败变异 |
| 主观质量、没法自动打分(创意写作、文风) | 手动对照 | 没有可信评分,自动优化只会自欺 |
三个做法不一样,但都守着同一条规矩:用来「改」的题和用来「验」的题必须分开。 否则就像拿考试原题去练 —— 分数好看,真上场就露馅。
而自动化的命门是打分得可信:评测有偏、评分太松、训练和验证没分开,机器会朝那个有偏的分数狂奔,越优化越歪,比人更快更彻底。所以上自动化之前先把评测做扎实;评测立不住,手动跑对照反而更安全。
一页带走
- 创建用 skill-creator,几分钟,不是难点。
- 别止步于「生成」—— 点开它的评测,跑「带 / 不带」对照,尤其盯住反例(能力范围外被带偏)。
- 看真实推理过程,别只看通过率 —— 通过率会骗你。
- 改 skill 靠加边界、不靠删;改完用同一组用例重测。
- skill 多了再上自动进化,记住一条:改和验的数据要分开。